Duplicate Records View¶
Configuring Duplicate Search Mechanisms¶
The duplicate search mechanism allows you to find duplicate records in the system and view them in clusters.
There are 2 ways available to customize search mechanisms using:
Data reindexing operation
Data matching pipeline
Before you start:
Create a data model with entities/reference sets that contain duplicate records.
Create an account with a role that is granted rights to administer the matching rules model and to the "Duplicates", "Operations", "Pipelines", and "System Parameters" sections, as well as access to the required entity/reference set. Access to sections is configured for a role that is subsequently assigned to the account.
Configuring with Data Reindexing Operation¶
Configure matching rules.
In the "Operations" section, create and run the reindexDataJob operation with the "Update matching tables data" flag enabled.
See the results in Duplicates section.
Configuring with Pipelines¶
In the System Parameters section, enable the Real-time data matching flag ("Data matching settings" section).
In the Pipelines section, configure the data matching pipeline.
Configure the matcing rules.
See the results in Duplicates section.
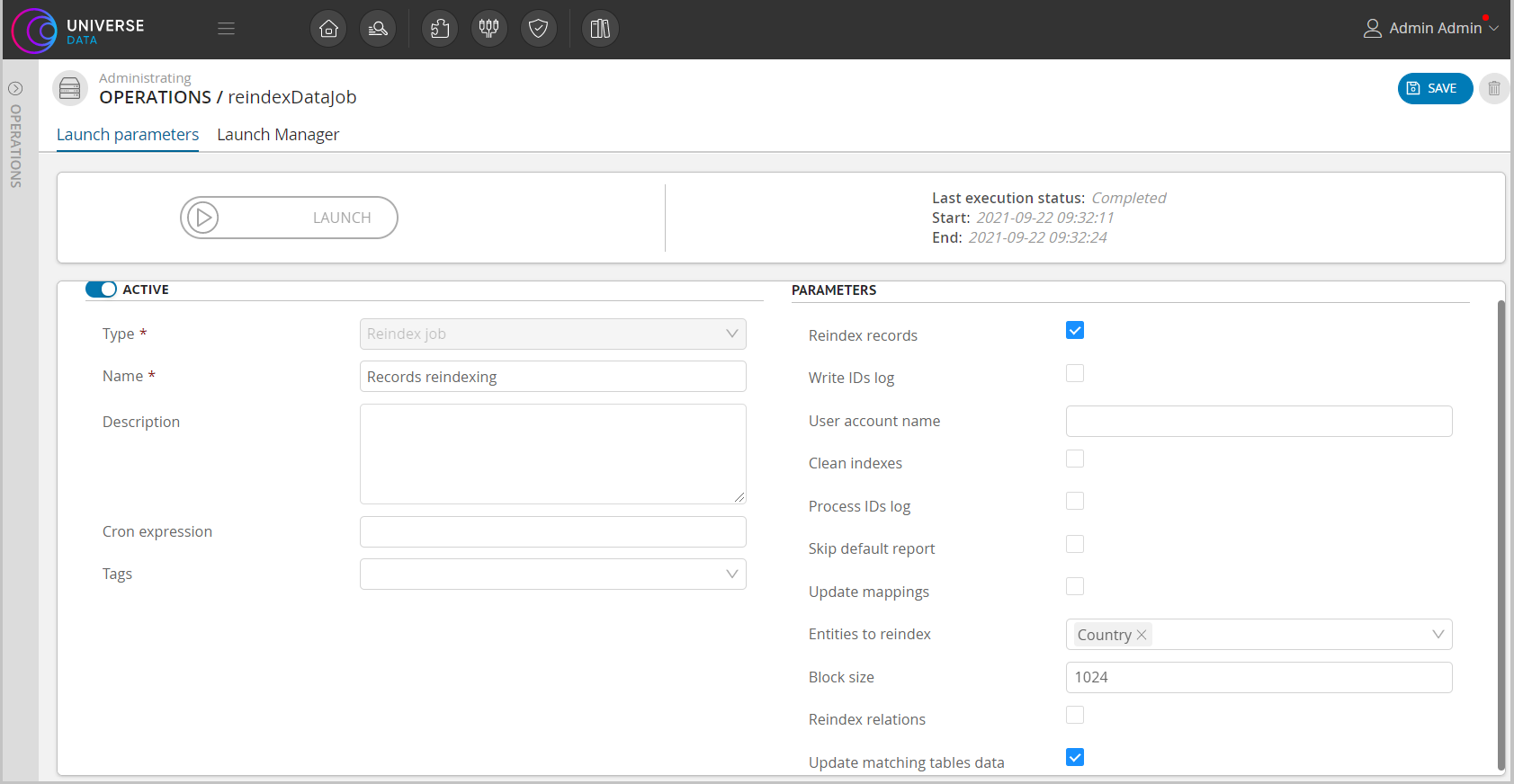
Figure 1. Re-indexing operation
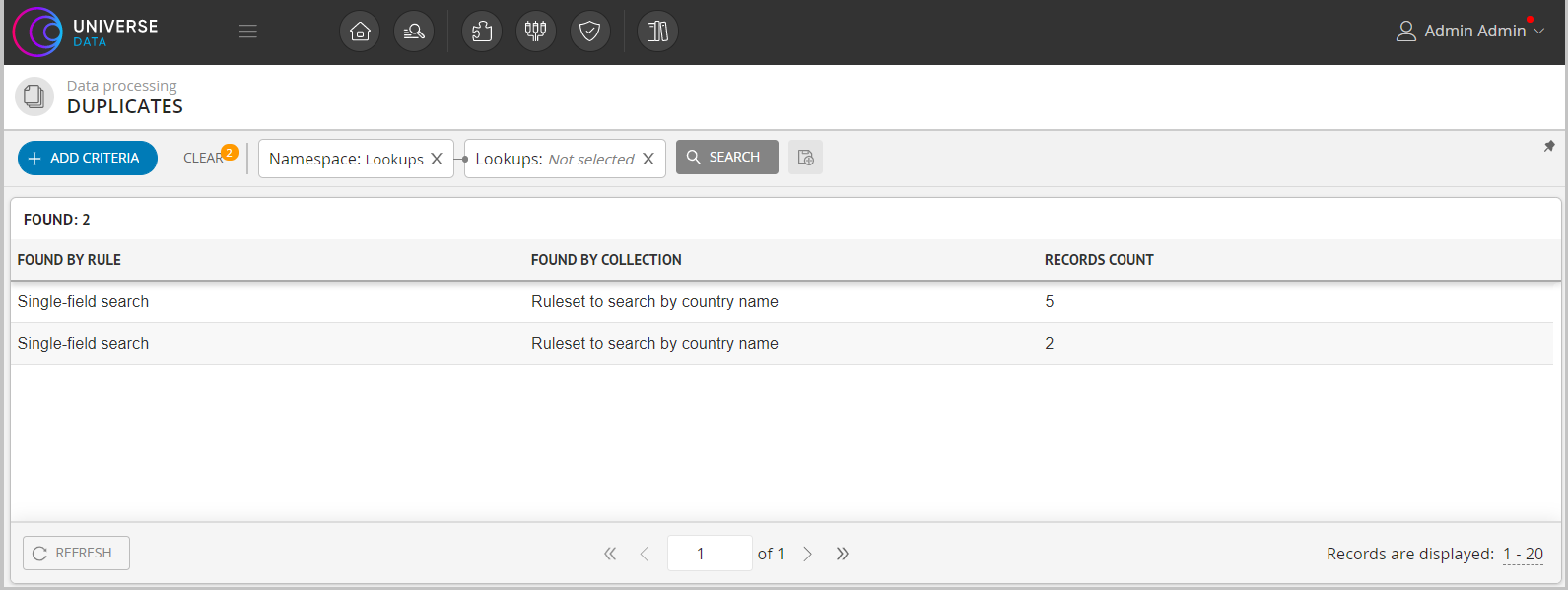
Figure 2. Duplicates section