How Inexact Duplicate Search Works¶
General Info¶
Inexact duplicate search is activated by setting matching rules when the Inexact Matching algorithm is selected. When the rule is triggered, a search for duplicate records is started. The search is performed in PostgreSQL storage.
The fuzzy matching algorithm is named org.unidata.mdm.matching.storage.postgres.service.impl.algorithm.InexactAlgorithm.
When searching for duplicate records for a column, two ways are used consistently. The first one is the main way, and the fastest. The second one is slower, but allows to find matches more accurately, and is used as an additional method.
Search Steps¶
Method 1
Step 1. The input is optimized. The input is turned into an tsvector object, converted to lower case, stemming (and reduced to canonical form). Stemming is the process of finding the stemma (the base of a word). Stemming makes the search engine independent of the word form (Figure 1).
Only dictionary stemming is used when the root of a word is highlighted.
A value of type tsvector contains a sorted list of non-repeating tokens, i.e. words normalized so that all word forms are reduced to one. Sorting and exclusion of repeated words is done automatically when entering the value, as shown in the example below. For more details, see tsvector and tsquery documentation.
SELECT 'a fat cat sat on a mat and ate a fat rat'::tsvector;
tsvector
----------------------------------------------------
'a' 'and' 'ate' 'cat' 'fat' 'mat' 'on' 'rat' 'sat'
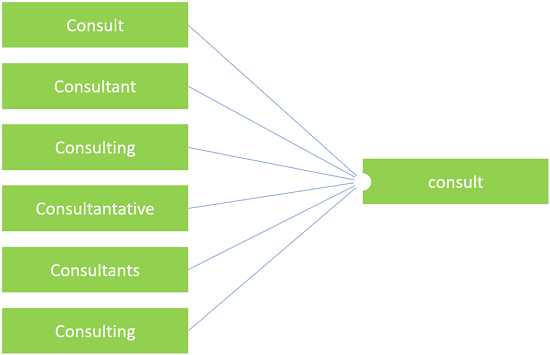
Figure 1. Stemming example
Step 2. Then similar manipulations are performed to turn the input into an object of tsquery type (full-text search). The tsquery value contains the searched tokens combined by the logical operators & (AND), | (OR).
Step 3. Then objects with different IDs (different match records) are compared in terms of matching the query to the token vector tsvector @@ tsquery.
This should result in matches, which are the search results.
Method 2
Step 4. If no match is found, the search by trigrams (a special kind of n-grams) is additionally used. The input is split into trigrams and turned into a SET (order does not matter, values are not repeated).
Letters and spaces fall into the trigrams, and punctuation symbols are cleared.
Two sets of two different records are compared for similarity by computing the Jaccard index: finding the private of the intersection of two sets and their merging.
Example: two records contain 14 identical trigrams in two sets. In total, the two sets contain 19 unique trigrams. So the similarity coefficient will be equal to 14 / 19 = 0.73.
The default coefficient is set to 0.65 as optimal, but can be changed if necessary.
Inexact Search Setup¶
Inexact duplicate search parameters are customized in the user interface when creating matching rules. The parameters are available if the Inexact Matching algorithm is selected. Possible parameters:
Content language (
contentLanguage) - the current implementation supports only Russian and English (default). Used for the 1st method.Similarity percentage (
similarityPercentage) - cuts off trigram sets by similarity coefficient. The value is in the range from 0.00 to 1.00 inclusive. Default = 0.65. Used for the 2nd method.Concatenation type (
concatenationType) - the type of token concatenation in tsquery objects. The current implementation supports & (AND) and | (OR). Default: & (AND). Used for the 1st method.